Python pour la Data Science : configurer son environnement de travail
Python est un langage de programmation extrêmement complet et souvent plébiscité pour conduire ses projets en Data Science. Sa grande flexibilité, le nombre très important de modules développés et de logiciels permettant de le faire tourner constitue une grande part de sa richesse. Mais elle est aussi souvent source de beaucoup de difficultés pour ses nouvelles utilisatrices et utilisateurs. Il est en effet parfois difficile de reproduire un environnement de travail simple et minimaliste, semblable à ce que l'on obtiendrait plus directement en utilisant R et RStudio.
Une des réponses à cette problématique est la solution Anaconda, mais elle nous semble trop lourde et souvent source de complications. C'est pour cela que cette semaine, on vous recommande un environnement de travail pour la Data Science avec Python, en se focalisant sur les outils qui nous semblent les plus pratiques et utiles au quotidien.
Installer Python et VSCode
Installation de Python
La première étape est bien sûr d'installer Python. Avant cela, vous pouvez tout de même vérifier que ça n'est pas déjà le cas en ouvrant le terminal de votre système d'exploitation et en tapant :
python --version
Attention, parfois l'alias utilisé par votre système ne sera pas
pythonmaispython3, il faut donc modifier les instructions données dans cette note en conséquence, ou modifier l'alias.
Si Python est installé, sa version va s'afficher dans la console, sinon vous recevrez un message d'erreur. Dans ce cas, rendez-vous sur la page du site officiel pour télécharger la version de Python qui vous convient. Je vous conseille la 3.12, qui est assez récente mais a déjà été éprouvée. Surtout, n'oubliez pas de cocher la case Add Python to PATH quand cela vous est demandé, afin de pouvoir accéder à Python en ligne de commande.
Une fois Python installé, vous pouvez vérifier que tout s'est bien passé en tapant à nouveau python --version depuis un terminal. Vous pouvez alors lancer depuis votre terminal une session Python en lançant l'instruction python. Mais nous allons préférer passer par un environnement de développement intégré, ou IDE.
Installation de VSCode
Le choix de l'IDE est déjà une première étape peu évidente, puisqu'il en existe de nombreux : Pycharm, Spyder, Jupyter Notebook... Nous vous proposons d'installer VSCode, parce qu'il est sans doute le plus populaire en ce moment, et qu'il peut être utilisé pour des scripts Python, mais aussi des notebooks Jupyter. Il supporte également de nombreux autres langages que Python (HTML/CSS, Javascript, C/C++, Ruby....) et pourra donc vous servir pour des projets plus tournés vers le développement Web. Enfin, il a un module intégré permettant d'utiliser Git sans ligne de commande, ce qui peut être très pratique pour une première prise en main d'un outil de gestion de versions.
Pour installer VSCode, suivez les instructions correspondant à l'OS que vous utilisez. Une fois installé, ouvrez-le et rendez vous dans l'onglet extensions que vous trouverez sur la barre latérale à gauche de votre écran :
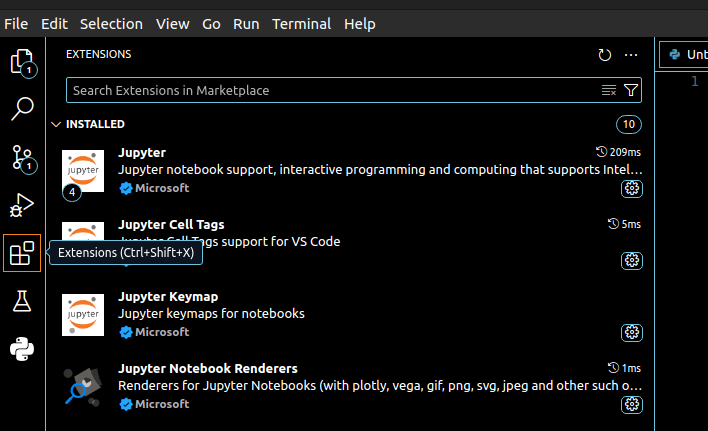
Ce sont ces extensions de VSCode qui lui permettent de gérer tant de langages différents. Vous pouvez d'ores et déjà installer les extensions Python et Jupyter.
Bonus : Installation de Git
Ça n'est pas l'objectif de cet article, mais on vous conseille fortement d'utiliser Git pour tous vos projets de Data Science. Pour cela, commencez par télécharger Git et créez-vous un compte sur Gitlab ou Github.
Si vous n'êtez pas à l'aise avec les lignes de commande, VSCode propose justement un outil intégré permettant de gérer vos fichiers et commits en clic-bouton, toujours accessible depuis la barre latérale :
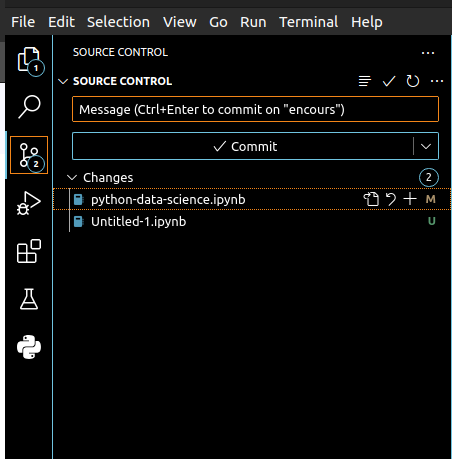
Pour se lancer avec Git sur vos projets de Data Science en Python, on vous conseille cet excellent article de Lino Galiana.
👋 Nous c'est Antoine et Louis de Statoscop, une coopérative de statisticiens / data scientists. Vous voulez en savoir plus sur ce que l'on fait?
Travailler avec Python sur vos projets
Ok, maintenant vous êtes prêts à vous lancer dans vos projets de Data Science. Il ne vous reste plus qu'à choisir et configurer un gestionnaire d'environnements avant de vous lancer enfin dans votre code Python!
Gestionnaire d'environnements
Un gestionnaire d'environnements vous permet de gérer les dépendances de votre projet afin que ceux-ci soient indépendants les uns des autres et plus reproductibles. En dehors du fait d'avoir des bibliothèques de packages propres à chaque projet, il vous permet également de gérer différentes versions de Python en fonction des besoins de chaque projet.
Là aussi, il existe différentes possibilités : virtualenv, pyenv, pipenv... Nous optons de notre côté pour le gestionnaire conda, qui nous semble pratique d'utilisation, notamment pour changer de versions de python simplement. Pour l'installer, nous vous proposons d'installer miniconda qui est une version allégée d'Anaconda nous permettant de faire tourner conda. Une fois conda installé, rendez-vous sur le terminal, accessible directement sur VSCode en bas de votre écran :

Vous pouvez maintenant créer votre premier environnement virtuel, en tapant dans la console :
conda create --name mon_premier_env python=3.12
Il n'est pas nécessaire de spécifier la version de python pour créer l'environnement mais c'est une bonne pratique, pour clarifier la version qui sera utilisée dans celui-ci. Vous pouvez aussi installer des packages directement à la création en mettant leurs noms à la suite de la version de Python.
Une fois créé, il ne reste plus qu'à l'activer avec :
conda activate mon_premier_env
Dans votre terminal, la mention (base) devrait être remplacée par (mon_premier_env), vous indiquant que votre environnement est bien activé.
Dorénavant, les packages que vous installerez seront installés seulement pour celui-ci. Nous allons ici installer pandas avec :
conda install pandas
Attention, ça n'est pas parce que vous utilisez
condacomme gestionnaire d'environnements que vous ne pouvez pas utiliserpippour installer des packages. On préfèrera cependant utilisercondaquand cela est possible pour faciliter les gestions de dépendances entre packages.
Enfin, pour sortir de votre environnement il vous suffit de taper :
conda deactivate
Les notebooks jupyter
Normalement, vous avez déjà installé les extensions Jupyter et Python sur VSCode. Vous pouvez donc cliquer sur File -> New File... -> Jupyter Notebook. Cela va vous créer votre premier notebook, avec une extension .ipynb.
On vous recommande les notebooks pour la partie exploration de vos données car ils vous permettent de faire tourner des blocs de Python et aussi d'intégrer du Markdown pour la mise en forme. C'est d'ailleurs des notebooks que l'on utilise pour rédiger nos notes de blog sur Python. Une fois votre notebook ouvert, cliquez sur Select kernel en haut à droite de votre fichier :
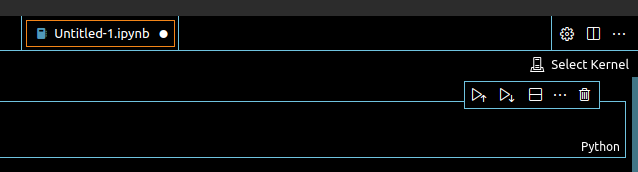
Dans Python Environments... vous allez normalement trouver votre environnement conda. Maintenant, créez une cellule de code et lancez :
import pandas as pd
Et là... catastrophe :
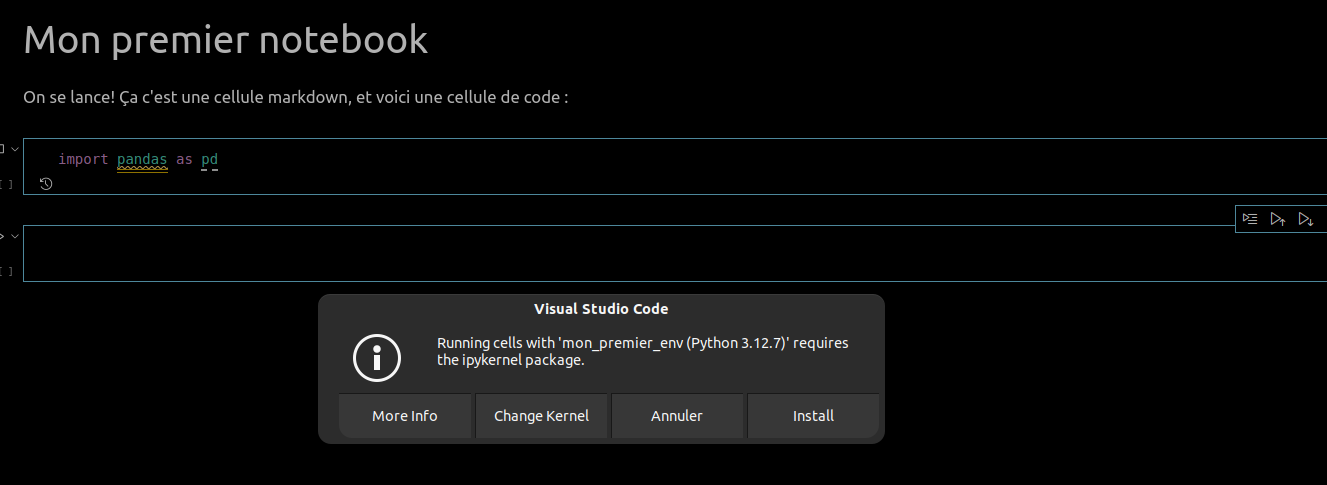
Mais non, c'est normal! On a juste oublié de vous expliquer quelque chose. Les notebooks s'appuient sur une version améliorée de Python, que l'on appelle IPython. C'est une surcouche interactive de python qui permet notamment de faire tourner Python par blocs de code, comme dans les notebooks. Vous pouvez l'installer en clic-bouton comme cela vous est suggéré, ou revenir dans le terminal, activer votre environnement et lancer :
conda install ipykernel
Maintenant, vous pouvez importer votre package pandas depuis votre notebook et lancer vos premières analyses exploratoires. Il vous reste encore probablement de nombreux problèmes à résoudre, mais on espère que cet article vous aura bien accompagné pour vous lancer!
C'est la fin de cet article! N'hésitez pas à visiter notre site et à nous suivre sur Twitter et Linkedin. Pour retrouver l'ensemble du code ayant servi à générer cette note, vous pouvez vous rendre sur le github de Statoscop.